MLP from scratch
Apr 2, 2024

Problem statement:
it's sometimes time-consuming to do repetitive works on number recognition, including grading, accountant, overall image recognition. Even though it is easy to build such a network using libraries such as TensorFlow or PyTorch. It's hard to learn the concept behind these black-boxes for ML learners.

(^^Try do things without them!^^)
Solution:
I'll demonstrate a basic way without using third party libraries to build a four-layer neural network.
Forewords: Neural network is really just math in some sense; it is inspired by neuron activation and a sense of interconnectivity. For our simple NN (neural network), I will create two hidden layer, which will work with the input layer and output layer to help identify digits.
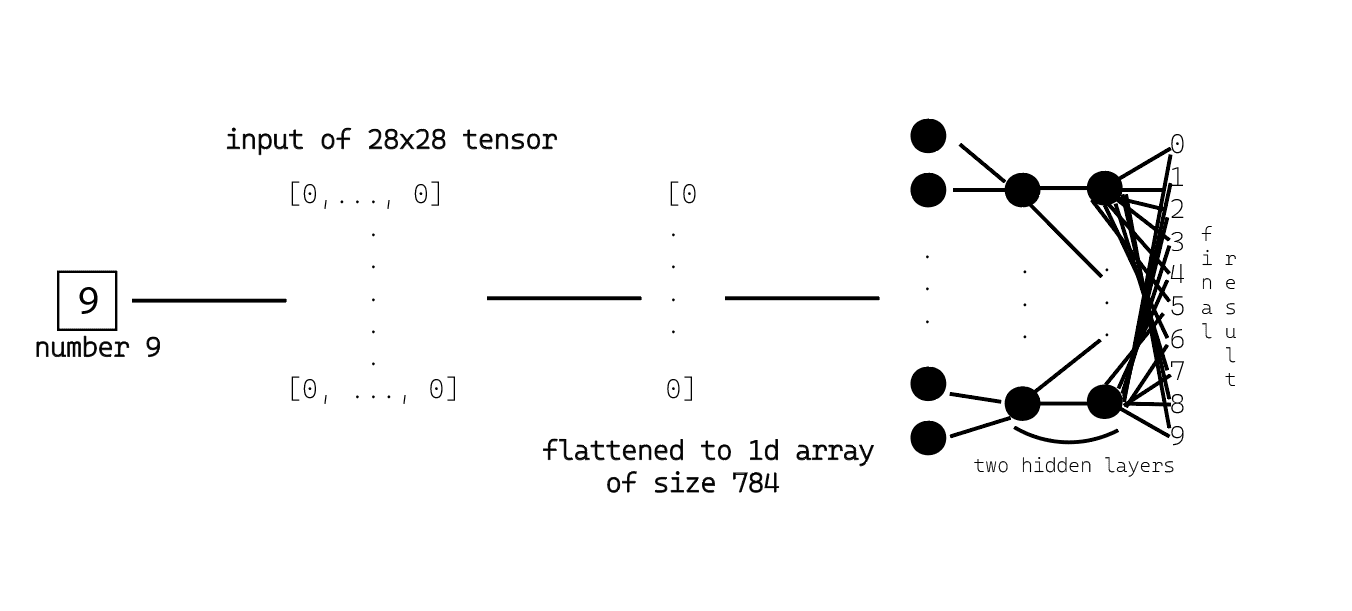
Structure of the Neural Network
overall view of the NN we're going to build:
zoomed-in-view of the NN:

Figures show a 784 x 10 x 10 x 10 neural network. The first 784 is taken by flattening the 28x28 pixel images, the middle two layers with 10 neurons are the hidden layer, the last layer is the output layer (digits 0-9).
Decision for activation functions:
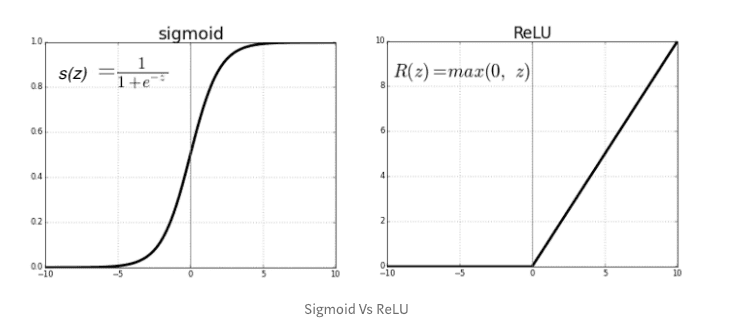
For the first hidden layer, I chose ReLU because of its efficient nature, and it can also provides a bit non-linearity.
For the second hidden layer, I chose softmax because it is often used for the last layer for prediction (classification).
Transform it into a math problem (how do we calculate output)
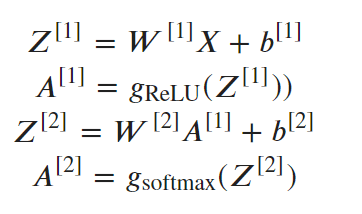
A1 and A2 are the final result for each neuron. W1, W2, b1, b2 are weights and biases. They can be interpreted as equation coefficient.
e.g. f(x)=ax^2+bx+c, here a,b are different weights, where c, an arbitrary constant, is the bias for the equation/function.
challenge to improve accuracy
Now we use randomly initialized weights:
the results looks… bad. For any input, we can guess the right number with only 8% chance! If we hope to perform better, we need to find a way to update the weight and bias to make the calculation more accurate.
Add a little calculus
To solve the problem, we return to the math palace:

and the sound rises: "use partial derivative to find the minimum". But minimum of what? — we have to determine the difference between our expected value and our computed value: we need a loss function:
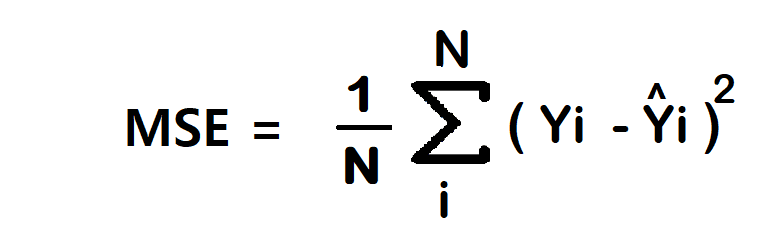
However, we can even make it simpler by going the other way around the MSE (mean squared error) loss function: we can simply calculate the average difference between the expected and actual output:
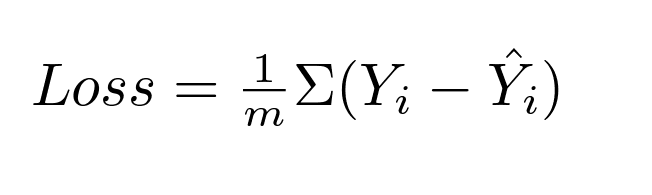
By finding the partial derivative of the loss in respect to every parameters, we can minimum the overall loss — making the prediction more accurate!
We then back-propagate (a fancy term to update parameters by utilizing the partial derivative) to update the parameters for our NN:
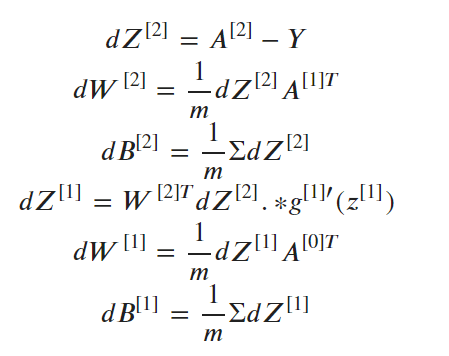
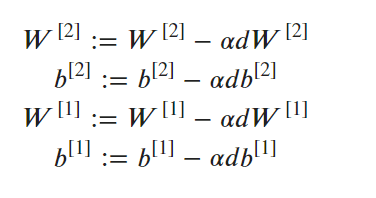
Run the code again

The result after 500 epochs with n=0.01 learning rates is quite disappointing. We see no obvious improvement on the accuracy rate.
Optimization
Normalize input layer
Think about how data converge. It's reasonable to conject more varied input layer take more time to study. An input of 0-255 has a range 255. That leads to the concept of normalization:
Normalize input value:
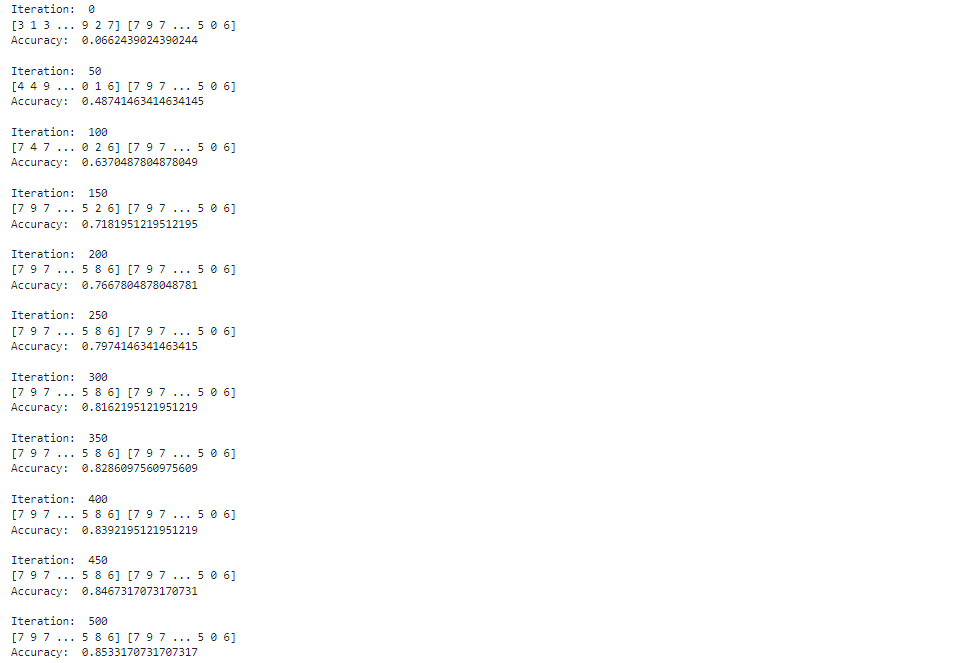
Conclusion
At the end of the day, we are able to obtain roughly 85% accuracy on digit recognition by constructing a four-layer fully connected neural network by combining knowledge of cognition, algebra, partial derivative, and normalization! Through challenges we met, we cross them with stronger selves.