从零开始的MLP
2024年4月2日

问题陈述:
有时候在数字识别方面做重复性工作会耗费很多时间,包括分级、会计和整体图像识别。虽然可以使用诸如TensorFlow或PyTorch等库构建这样的网络,但对于机器学习者来说,学习这些黑盒背后的概念是困难的。

(^^试着不依赖它们去完成任务!^^)
解决方案:
我将演示一种基本方法,即不使用第三方库构建一个四层神经网络。
引言: 神经网络在某种意义上真的只是数学;它受神经元激活和相互连接的启发。对于我们的简单NN(神经网络),我将创建两个隐藏层,它们将与输入层和输出层一起工作,帮助识别数字。
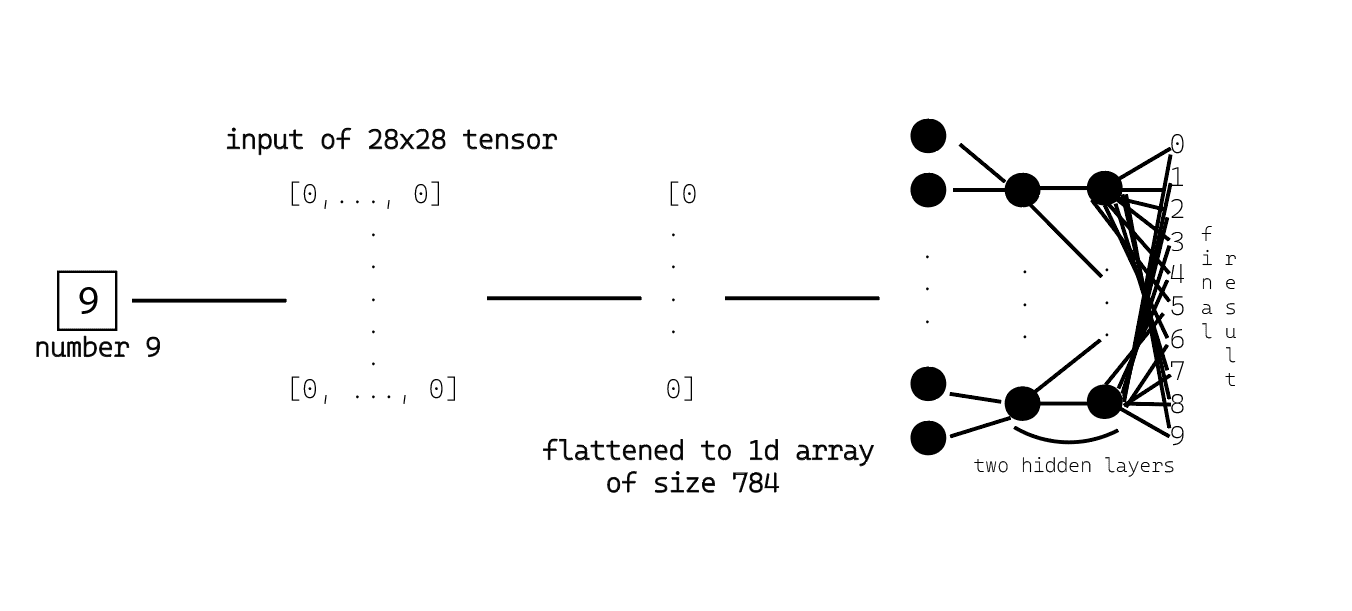
神经网络的结构
我们要构建的NN的整体视图:
NN的放大视图:

图中展示了一个784 x 10 x 10 x 10的神经网络。前面的784是通过将28x28像素的图像展平得到的,中间的两层有10个神经元构成的隐藏层,最后一层是输出层(数字0-9)。
激活函数的选择:
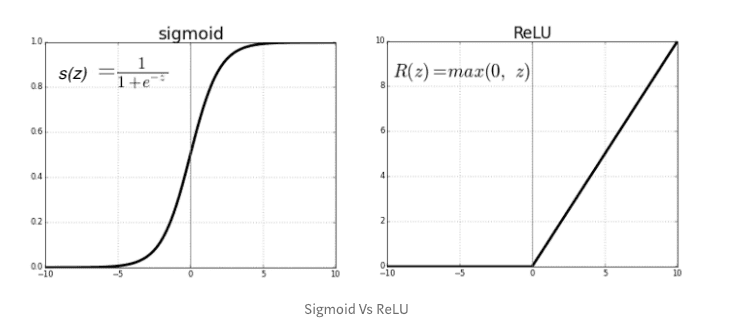
对于第一个隐藏层,我选择了ReLU,因为它的效率很高,而且还能提供一些非线性。
对于第二个隐藏层,我选择了softmax,因为它经常被用作预测(分类)的最后一层。
将其转化为数学问题(我们如何计算输出)
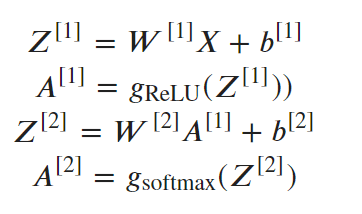
A1和A2是每个神经元的最终结果。W1、W2、b1、b2是权重和偏差。它们可以被解释为方程系数。
例如 f(x)=ax^2+bx+c,在这里a、b是不同的权重,而c,一个任意的常数,是方程/函数的偏差。
提高准确性的挑战
现在我们使用随机初始化的权重:
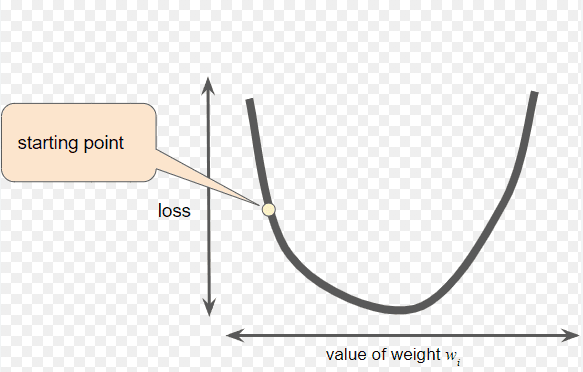
结果看起来……糟糕。对于任何输入,我们只能以8%的概率猜对数字! 如果我们希望表现得更好,就需要找到一种方法来更新权重和偏差,使计算更精确。
添加一点微积分

声音升起:"用偏导数找到最小值"。但最小值是指什么?—我们必须确定预期值与计算值之间的差异:我们需要一个损失函数:
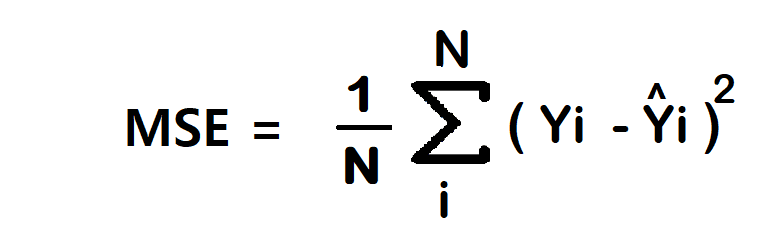
然而,我们甚至可以通过另一个方式简化,即MSE(均方误差)损失函数:我们可以简单地计算预期输出和实际输出之间的平均差异:
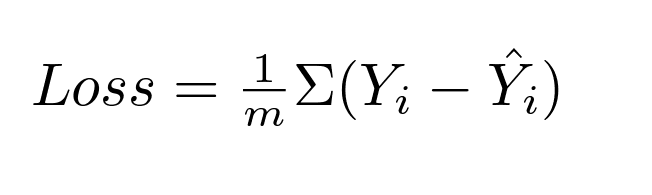
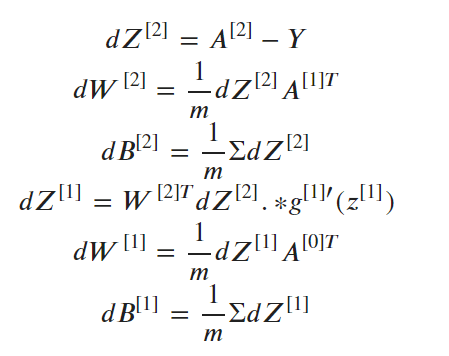
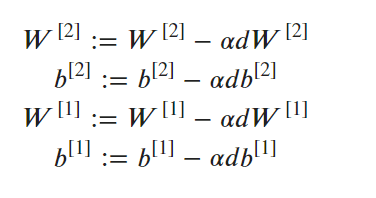
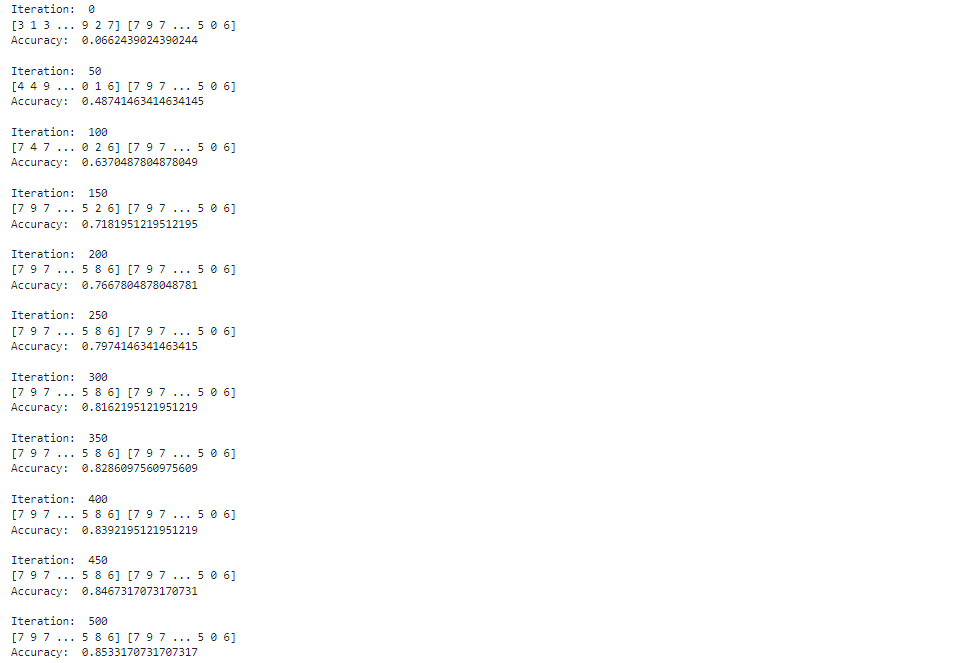
重新运行代码

优化
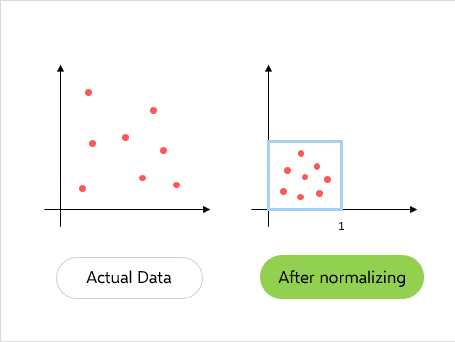
规范化输入层
结论
最终我们成功的在训练集中获得了百分之85的成功率。这个项目成功的运用了简单的MLP,以及关于认知学,偏微分,以及规范化样本的知识。我们成功的克服了遇到的困境,并让这一个4层神经网络取得部分成果